Why not 0.06?

Steve Accera asked me an interesting question a few months back. Why is 0.05 the cut-off for a p-value to be considered statistically significant?
To understand the answer to this question, we first have to talk about how to interpret a p-value in the first place. For the expanded explanation, click here.
Remember, that the p-value is the probability of “observing the data” (which is really a blanket statement for any comparison you might perform between two or more groups, depending on the test), GIVEN the null hypothesis. It is NOT the probability that the null hypothesis is true.
It is a matter of convention that we consider a p-value of 0.05 to be sufficiently low to “reject the null hypothesis.” That is to say that it’s so unlikely to observe the data we collected (or more extreme data) that the only way to explain it would be if the null hypothesis was wrong.
But there’s nothing wrong with setting the threshold higher or lower than 0.05; provided you do it BEFORE you do the experiment; otherwise, you’re just applying your own biases and wishes on the interpretation of your data. It all comes down to how much probability you’re willing to risk.
In a casual poll of Facebook “like”-ers, 58 people were convinced to answer my poll, which was to ask, “If someone flipped a coin 60 times, how many heads (or tails) would it take for you to become suspicious that the coin was not a fair coin (i.e. the probability of a heads was not 0.5)?
This is not a trick question. There isn’t a right answer, because everyone’s opinion of “suspicious” is different, and therefore subject to their own impressions, experiences and intuition. When you become suspicious is entirely up to you. What’s interesting is that the respondents of my poll are generally pretty generous folks 🙂
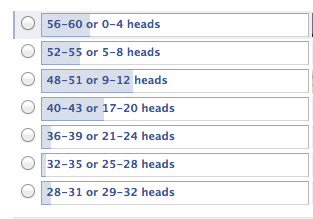 |
| Casual poll of 58 incredibly good-looking respondents (out of 890 views, so maybe it’s biased. Or I’m biased. If only I had managed to fit the word, “boobies” in there somewhere…) |
The p
So, if we did ran an experiment to determine if a coin was unfair (i.e. the probability of flipping a heads was NOT 50%,) and the coin flipped 37 or more heads or 22 or fewer heads, we would calculate a p-value of 0.05 or less. We would interpret this p-value as being “statistically significant” AND we would therefore conclude that since the likelihood of observing more than 37 or less than 18 heads is so unlikely that the coin must be unfair.
There’s a whole OTHER blog post behind this one, involving decision theory and how people make decisions, but based on the casual poll, there’s a nice normal-ish-looking distribution that centres around 48-51 heads or 9-12 heads, which actually corresponds to a p-value of 0.000003 (for 48 or 12 heads), or more practically speaking, a p-value less than 0.01 (and yes, it is kinda skewed, but mostly because of the ceiling effect of the possible responses.)
Selecting an alpha level prior to a study, is generally done by convention. There are a minority of studies (none in fitness or nutrition that I’ve seen) that might select an alpha that is less than 0.05 (usually in instances where the study can only ever be done feasibly once. Ever.) Ronald A. Fisher (after whom the Fisher Exact Test is named, and who is credited with bringing it up in the first place, even though he, himself wasn’t a big fan of arbitrary cutoffs) suggested that 0.02 would be a stronger value. However, rare is the situation where a larger cutoff would be acceptable (though, again, Fisher himself was known to accept p-values greater than 0.05, depending on the question, and almost always AFTER he had calculated the p-value in the first place, which we would, today, consider a biased opinion–yeah, I’m going to statistics hell for saying that about Fisher.)
The reason why Fisher thought 0.05 was reasonable (and this probably has a lot to do with why we still think of it as reasonable) was because there is a balance between being over-exclusive and missing out on potentially important findings, and being over-inclusive and accepting a lot of garbage. A cut-off value of 0.05 is considered sufficiently lenient that you’re not going to miss something possibly important but hard to detect because of small numbers. It’s not sufficiently stringent enough that you can hang your hat on it either though. Obtaining a p
So back to Steve’s question of, “Why not 0.06?” My answer comes in two parts:
1) From the casual poll on something fairly trivial like a series of coin flips, there appears to be a reluctance to accept even a 0.05 level. Only 7 out of 58 respondents (or 12%) chose coin flips equivalent to p-value cutoffs of greater than 0.05. When it comes to getting the RIGHT answer, most people tend to want more certainty than a 1 in 20 chance that it might be nothing.
2) Even at a significance level of 0.05, the odds of being wrong are still quite generous. The first problem of raising the cut-off point to 0.06 (particularly if it’s AFTER you’ve already calculated the p-value on your data) is, “Why 0.06 in study A, but not study B?” The second inherent problem in raising the cut-off point is that you inadvertently commit yourself to having to verify MORE studies that show “promising, p<0.06” results when you’re already struggling to show whether the p
In the end, it would appear that p
Hope that clears things up more than it muddies them.